In this blog post, we will speak about celery how and why it can be interesting for you.
We know all of the benefits of consuming celery regularly. Celery is also a powerful tool used in modern built applications!

Celery can be an interesting tool to implement for several reasons, especially if you’re working on projects that require background processing, task management, or distributed systems.
A bit of theory:
Asynchronous Task Processing
Celery allows you to offload long-running or resource-intensive tasks (like sending emails, processing images, or running heavy calculations) to the background, so your application stays responsive.
This is particularly useful in web apps, where you want to return responses quickly to the user.
Distributed Architecture
Celery can run across multiple workers, which means you can scale horizontally by adding more workers as your workload increases.
This makes it a great fit for microservices or systems handling lots of background jobs.
Flexibility with Task Scheduling
Besides real-time processing, Celery supports periodic tasks (like cron jobs), making it useful for scheduling maintenance jobs, recurring notifications, or periodic data scrapes.
Integration with Many Backends
It works with message brokers like Redis, RabbitMQ, and others, allowing flexibility depending on your infrastructure.
You can also plug it into various result backends to store task results (databases, caches, etc.).
Retry and Error Handling
Built-in support for retrying failed tasks with customizable strategies (exponential backoff, etc.), making it robust for unreliable environments (like flaky external APIs).
Monitoring & Insights
Tools like Flower (a web-based monitoring tool for Celery) give visibility into tasks, queues, and worker health.
This makes it easy to spot bottlenecks or failed jobs.
Decoupling Components
By using Celery, you naturally decouple your app logic into smaller, manageable, and reusable tasks.
This improves the overall maintainability and testability of your system.
Wide Adoption & Community Support
Celery is widely used in the Python ecosystem, meaning you’ll find lots of documentation, tutorials, and community plugins.
This reduces the learning curve and makes debugging easier.
Good Fit for Event-Driven Systems
If your system benefits from event-driven architectures (e.g., trigger tasks based on user actions, webhook callbacks, etc.), Celery fits well.
Practice
Before starting let’s install celery
pip install celeryAsynchronous Task Processing
In this example, let’s imaging a scenario without the asynchronous and with the asynchronous task
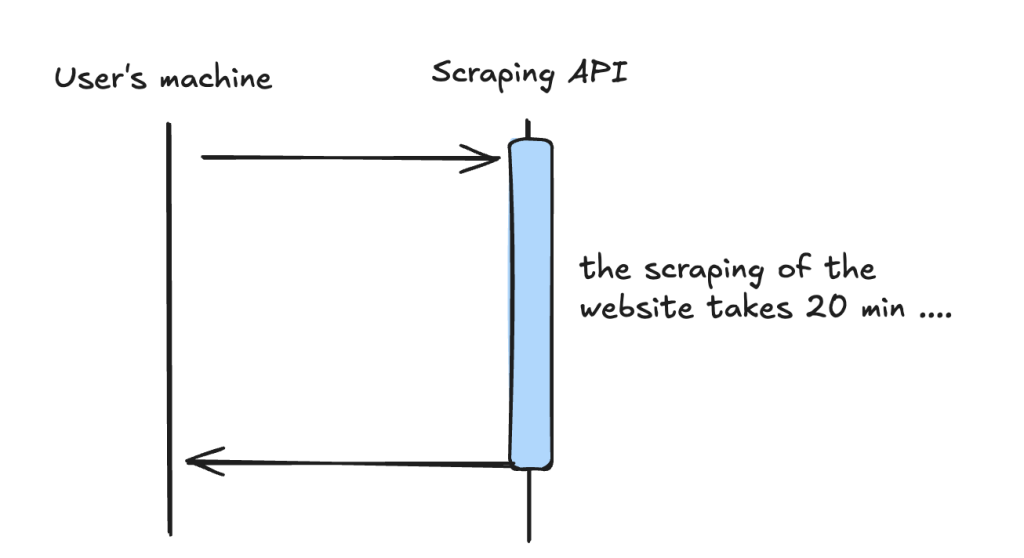
Synchronous process:
1 – User sends a request
2 – The Server is doing the job
3 – Once done the server is returning the response
During this time the user was expecting the response for 20 min.
Blocking him to do any other actions on the page where it was navigating through.
Asynchronous process with celery
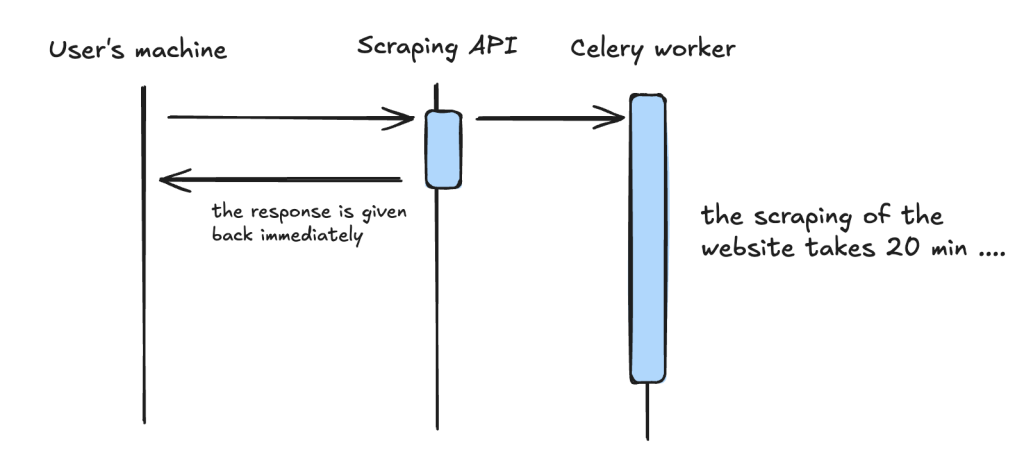
Distributed Architecture
By default one worker can handle 8 tasks at the same time.
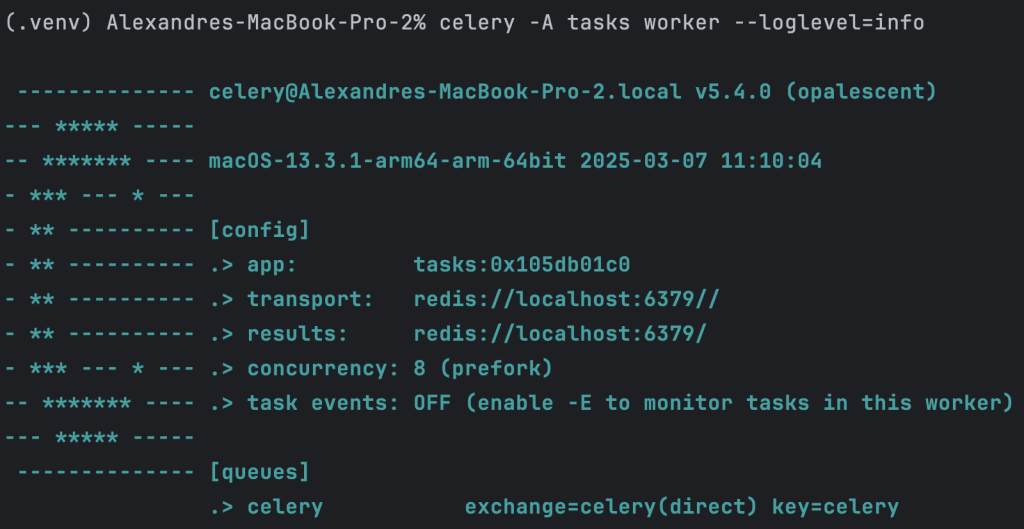
We can increase the number of workers by using the option –concurrency when starting the celery worker manager
celery -A tasks worker --loglevel=info --concurrency=1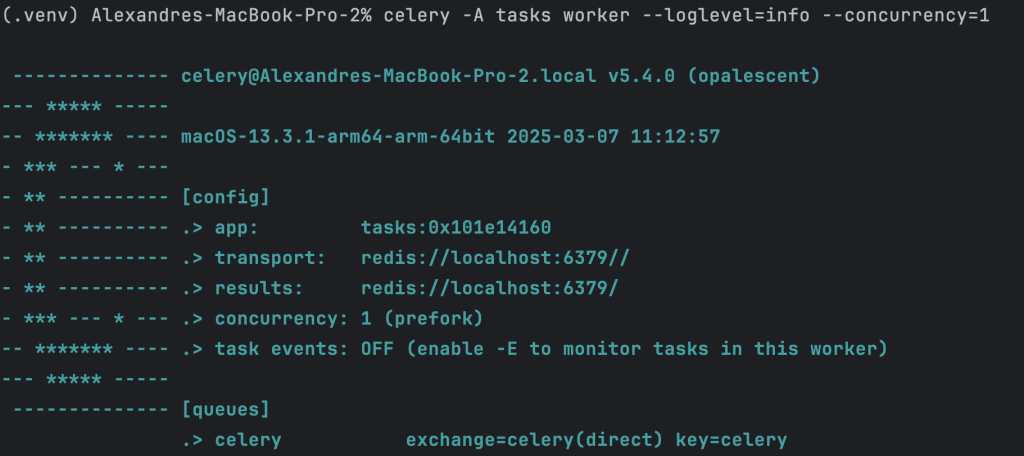
Total time taken with one worker: 30 seconds
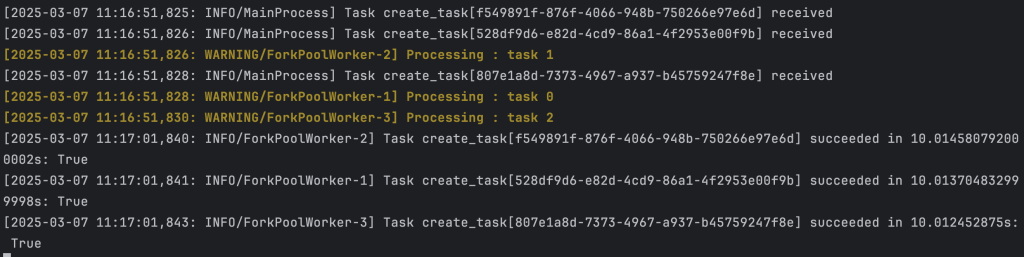
celery -A tasks worker --loglevel=info --concurrency=3Total time taken with three workers: 10 seconds
Flexibility with Task Scheduling
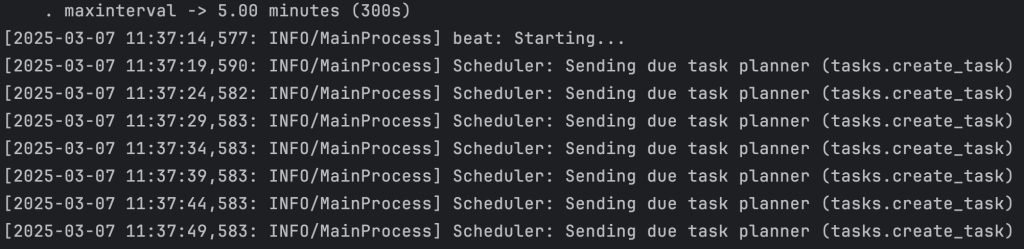
Let’s look at how to schedule a recurring task with celery. We define the configuration for the recurring task.
# tasks.py
celery.conf.beat_schedule = {
'planner': {
'task': 'tasks.create_task',
'schedule': 5.0, # start task every seconds
},
}We need to run another on the celery command which will start the tasks for us every few seconds.
celery -A tasks beat --loglevel=infoMake sure that the worker is still running to receive and handle the tasks
celery -A tasks worker --loglevel=info --concurrency=3Output:
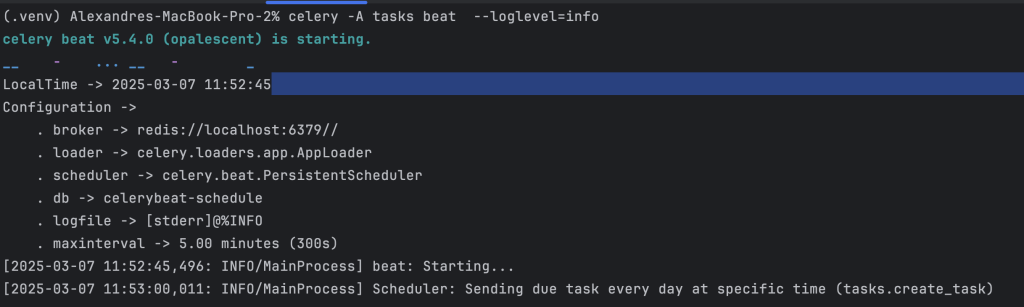
Now, let’s look at how to schedule a task every day at a specific time
elery.conf.beat_schedule = {
# 'every 5 seconds': {
# 'task': 'tasks.create_task',
# 'schedule': 5.0,
# },
'every day at specific time': {
"task": "tasks.create_task", # <---- Name of task
"schedule": crontab(
hour='11',
minute='53',
)
},
}Output:
Integration with Many Backends
Retry and Error Handling
Explicit retry mecanism
uvicorn target:appLet’s modify a bit the task to call this target API.
@celery.task(bind=True, max_retries=3, default_retry_delay=20, name="create_task")
def create_task(self, task_type):
print(f"Processing : task {task_type}")
try:
response = requests.post("http://localhost:8000")
response.raise_for_status()
except HTTPException as ex:
raise self.retry(exc=ex)
return Truebind=True is way to pass an object representing the current task being run as a parameter of the task.
From the docstring of celery.task
App Binding: For custom apps the task decorator will return a proxy object, so that the act of creating the task is not performed until the task is used or the task registry is accessed.
max_retries: Maximum of retries allowed
default_retry_delay: delay (in seconds) to retry
raise_for_status is used to raise a HTTP Exception in case the status code is different than 2XX range
self.retry: allows us to retry the current task based on parameters passed in the decorator task
[2025-03-14 12:17:04,183: ERROR/ForkPoolWorker-8] Task create_task[05ad8902-d1b8-4168-bfca-dba789d318ad] raised unexpected: HTTPError('408 Client Error: Request Timeout for url: http://127.0.0.1:8000/flaky-endpoint')
Traceback (most recent call last):
File "/Users/aldazar/Projects/celery_playground/.venv/lib/python3.9/site-packages/celery/app/trace.py", line 453, in trace_task
R = retval = fun(*args, **kwargs)
File "/Users/aldazar/Projects/celery_playground/.venv/lib/python3.9/site-packages/celery/app/trace.py", line 736, in __protected_call__
return self.run(*args, **kwargs)
File "/Users/aldazar/Projects/celery_playground/5_retry_and_error_handling/tasks.py", line 27, in create_task
response.raise_for_status()
File "/Users/aldazar/Projects/celery_playground/.venv/lib/python3.9/site-packages/requests/models.py", line 1024, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 408 Client Error: Request Timeout for url: http://127.0.0.1:8000/flaky-endpoint
[2025-03-14 12:18:01,427: WARNING/ForkPoolWorker-8] Processing : task 1Monitoring & Insights
pip install flower
celery -A tasks.app flower
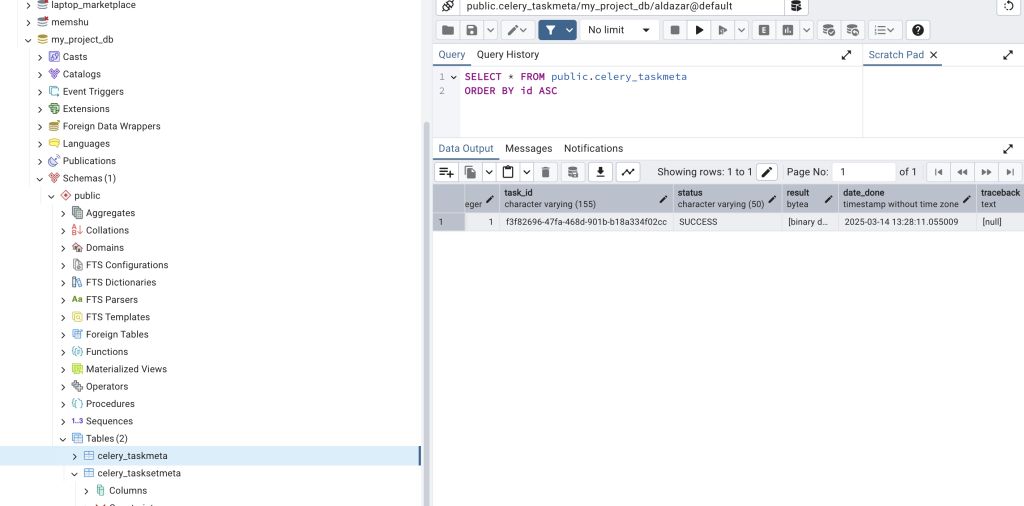
psql postgres
SELECT rolname FROM pg_roles;
sudo -u postgres psql -c "ALTER USER aldazar PASSWORD 'postgres';"-- Create the database
CREATE DATABASE my_project_db;
-- Create the user with the desired password
CREATE USER admin WITH PASSWORD 'password';
-- Grant all privileges on the database to the user
GRANT ALL PRIVILEGES ON DATABASE my_project_db TO admin;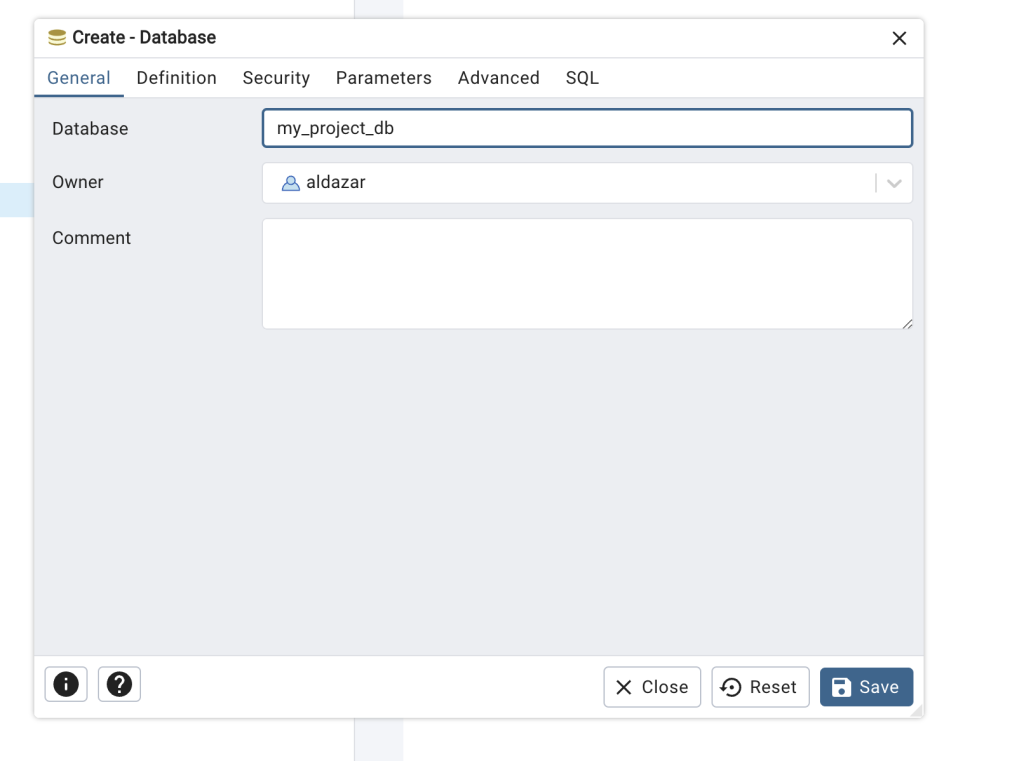
Curses events
Look at the tasks without any user interface directly from the terminal
celery -A tasks events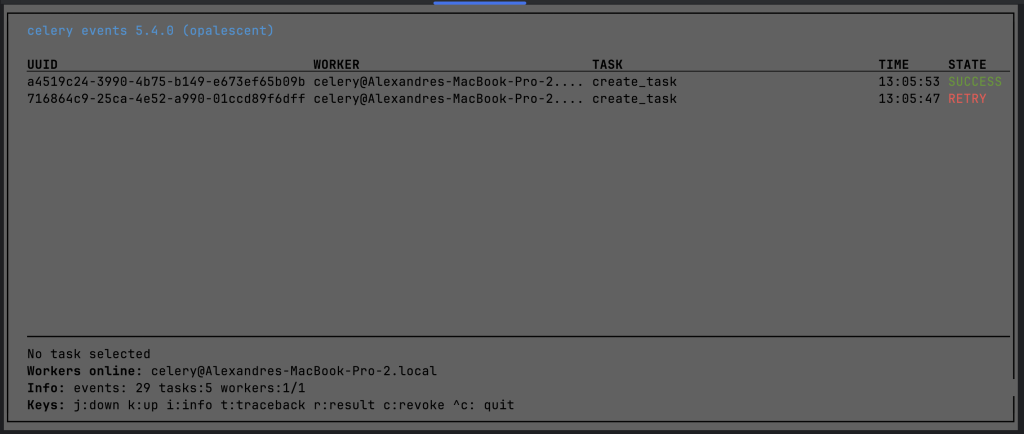
Monitoring tasks with celery
1 – to enable task events when starting the worker
celery -A tasks worker -l INFO -E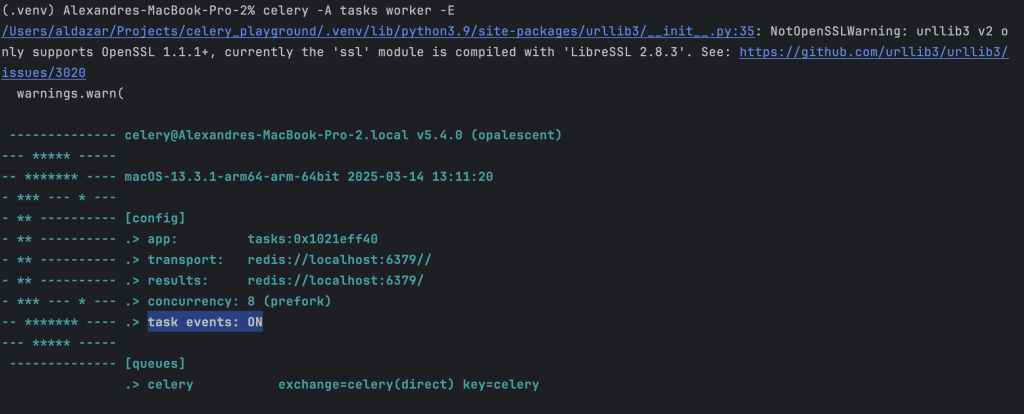
Prometheus
pip install prometheus_client
pip install celery-prometheus-exportercelery-prometheus-exporter --broker localhost:6379
Early in my career, I specialized in the Python language. Python has been a constant in my professional life for over 10 years now. In 2018, I moved to London where I worked at companies of various sizes as a Python developer for five years. In parallel, I developed my activity as a Mentor, to which I now dedicate myself full-time.